NLP with Neural Network
本文是使用神经网络的方法进行自然语言处理的技术路线,以Stanford的CS224d课程为主,仅供参考。
1.一些必要的知识
1.线性代数,包括矩阵的运算,以及模,秩,特征值、特征向量以及和导数求解相关的矩阵知识(比如牛顿法中的Hessian Matrix)等。
2.概率论,包括概率密度函数,条件概率,联合概率,贝叶斯,协方差等。
3.凸优化,包括什么是凸集合,凸函数,如何进行。
2.课程正文
2.1词向量
本小节的重点是word vectors,介绍了词汇向量化的几种经典的方法。
首先介绍了使用descrete representation(比如one-hot)的方法进行词汇向量化的方法,其中一个典型的代表就是使用WordNet这样的字典,但是直接使用字典的方式来将词汇向量化,有很多问题存在:
- 会丢失很多词汇的本意细节(nuance), 比如一词多义的问题没办法保留多个意思。
- wordnet中的词汇有限,不能及时覆盖所有的词汇。
- 不能直接用来计算词汇之间的相似性。
第二种表示方式是使用neighbors的count来表示词汇,其思想是一个词可以用句子中它周围的词来表示。该种方法有两种的选择,一个是使用“full document”,另一个种是使用“windows”;前者的思想又引出了latent semantic analysis(可以用于文章分类等);使用neighbors来进行词汇的表达存在的问题包括:
- 需要维护高维矩阵,该矩阵需要大量的存储空间
- 模型的鲁棒性不高
由此,针对上述问题,提出的解决方式是进行矩阵降维,常用的方法包括:SVD(对于矩阵,时间复杂度为,其中),此外SVD分解的方法实现词汇向量化对于新词汇的加入不是很友好。
除了第二种方法中的使用临近词汇的count来表示,并通过一定的降维方式来实现word embedding外,还有一种方式是直接生成低维向量(其实这个低维一般也有几百维)。该种方法的思想是通过训练机器学习模型来“modeling”词向量,其代表方法包括Google的word2vec,其特点是对于新的词汇有较好的接收。该种方法通过建立目标函数,使用梯度下降(链式法则)的方法来maximize/minimize目标函数。
其基本步骤包括:
- 定义目标函数/Cost
- small random numbers初始化参数(对于Word2vec 参数为2Vd个数,其中V为字典长度,d为每个word的词向量维度,这里的2是因为对于每一个词有v,u两个向量来表示,一般使用词向量时,v+u作为结果)
- 对Cost进行SGD(Updating parameters with each window in Word2Vec)
针对Word2vec这种方法可以展开思考一些问题,比如每个window的词比较少,这样梯度是稀疏的(参数中只有2c+1个参数需要更新,w为window长),为解决该问题,只处理(更新)目标2c+1个参数(by only update certain columns of full embedding matrix U(left or right words) and V(center word))。
下面给出Word2Vec的目标函数的子项(每一个窗口内的neighbor词均对应下面给的exponent概率):
In above formula, we could find that we need to sum all the exponent function of neighbor words, which is computationally expensive. Hence, we change the objective function.
改成上式后的方法,叫做Negative Sampling, 其中可以取10,20这样的数;是sigmoid function。;Rondom函数有特定的设计,corpus中频繁出现的词,更有可能被选出来,但是这个可能性要低于它在corpus中出现的频率。我们认为Negative Sampling相比于之前的目标函数,增加了额外的信息:使不相关的(random)的词汇距离尽可能远。
2.2 Word window classification and nerual network
分类,在自然语言中的用处包括:从词到词的预测(比如说补全句子),情感分析,命名实体识别(named entity),分析决策(sell/buy decision),翻译等。下面将给出分类的相关内容。
LR,Logistic Regression(之前blog里介绍过的SVM只会给出分类的结果,而LG会给出分类的概率,比如分为正类的可能性),LG是使用sigmoid函数,相当于线性回归之后加入了Logistic变换。
NLP的Classification与传统意义上的classification的不同在于,NLP中除了训练模型的参数外,还可以把词向量加入到需要训练的参数中,并且,当训练集非常大时,同时进行词向量的训练(update),效果较好。
然后引入Window classificaition,一般对单个word的分类,在实际场景中很少用到,此外,word在句子中包含的信息会更多,因此,我们对NLP进行分类时,一般是指window classification。
单层神经网络(one hidden layer nn/three layers nn),对于windows classification问题,比如其中一个sentence窗口是”Museums in Pairs are amazing”,用来表示,且,然后根据我们设计的隐层metric(结点的数目),可以假设,由隐层到输出层的映射,可得,s即为分类的得分(score)。
如果说”Museums in Pairs are amazing”是True window,那么可以定义一些corrupt windows,比如(not all museums in Paris),通过训练,使true windows的得分高,corrupt windows得分低。比如可以将目标函数定义为:
该目标函数叫做Max-Margin Objective function,在实际操作中一般忽略左侧的max和0。对于每一个true window,都需要sample几个corrupt windows。
这里尝试推导的梯度:
当为sigmoid function时,,且有,其中称为local error signal,称为local input signal
接下来介绍第一个tip,反向传播计算时的参数复用,,作为activation 的error message (responsibility). 这样就可以省去计算了;同理可以求得biases ,可知是完全不增加新的计算量的。
第二个tip,Multi-task learning/Weight sharing。其思想是可以通过参数共享来同时训练多个tasks,比如NLP中的词性标注POS(Part-of-Speech) ,NER(Named Entity Recognition)可以同时进行,两个模型在隐层使用同样的weights,但在output层使用不同的weights参数。
接下来介绍了一些训练神经网络的细节:
1. 激活函数:1)(sigmoid),;
2):,并且,
3) ,
2. Gradient check,作为神经网络中的“debug”,gradient check可以帮助我们确定梯度计算的准确性。梯度的计算是通过pen-and-paper(推导出来的导数式),而check的时候,通过数值近似的方法来计算:,其中非常小,为数量级,然后比较两个计算结果,确定其相差不多。
3. Model simplification, start from simplest model to find bugs.
4. Parameter Initialization, 假设,,并且,这样,对于,过大,对导致tanh的梯度接近于0,不利于优化。通常情况下我们将初始化为0, ,并且,其中是上一层layer,units的个数。注意上式是tanh的参考值,对于sigmoid,应该乘上4.
5. SGD, 更新参数的频率,对于大的数据集,SGD优于all batch methods。对于小的数据集,L-BFGS 或者Conjugate Gradients方法更合适。比较常用的是mini-batch SGD, 20到1000大小的batch,这样也有利于并行计算。对于参数的更新,除了最基础的learning-rate gradient,还有一些延伸:
1)Momentum,由于SGD的更新完全依赖于当前的batch,这种更新方向可能是十分不稳定的,于是在此处引入momentum,在该次batch的更新中,保留上次更新的影响。,的初始值是0,为0到1的正数,可取0.9。Momentum的收敛速度更快,而且能够跳出局部最优点。除此之外,还可以改变learning rate :当training validation error不再改变时,减0.5;此外对于频繁出现的word,可以使用较低的learning rate,对于rare的word,使用较高的learning rate。
6. Regularize,当遇到样本小,参数多的情况,可能会有过拟合的现象发生,这里引入解决办法:1,最简单的方法是改变Model Size,减少结点的数目,层的数目。2,Standard L1 or L2 regularization on weights。3,early stop,use parameters that gave best validation error。4,Drop out,1)在training time,随机将50units结点的输入设为0;2)在testing time,将所有的weight除以2(修补1带来的部分影响)
2.3 Language model
A language model computes a probability for a sequence of words:。有了language model,便可以知道哪些word拼凑起来更像一个句子,比如the cat is small比small the cat is更符合我们对于句子的定义,这些特性在machine translation中帮助我们进行翻译。我们知道对于条件概率:
不同于之前讲过的windows classification,在language model中fixed window 可能不是很合理,前5个/10词汇未必一定能很好地引出下一个词汇,因此,我们在这里引入RNN(Recurrent NN)
输入是word vectors:,其中是whole corpus的大小。对于hidden层的一个unit,,输出为,其中,其中为hidden layer的数据维度。,为word vector的维度,。因此得到,是word vocabulary的概率分布。每个predicting word都对应完成的word vocabulary distribution。因此我们定义目标函数为cross entropy loss:
最后
这里需要指出rnn的问题,我们知道由于input层(hidden层的time step)比较长(这个长度由corpus的sentence长度决定,可以是5也可以是50,也可以是一本书几万个word),这就会导致gradient vanishing 和gradient explosion。下面推导gradient vanishing的原因。
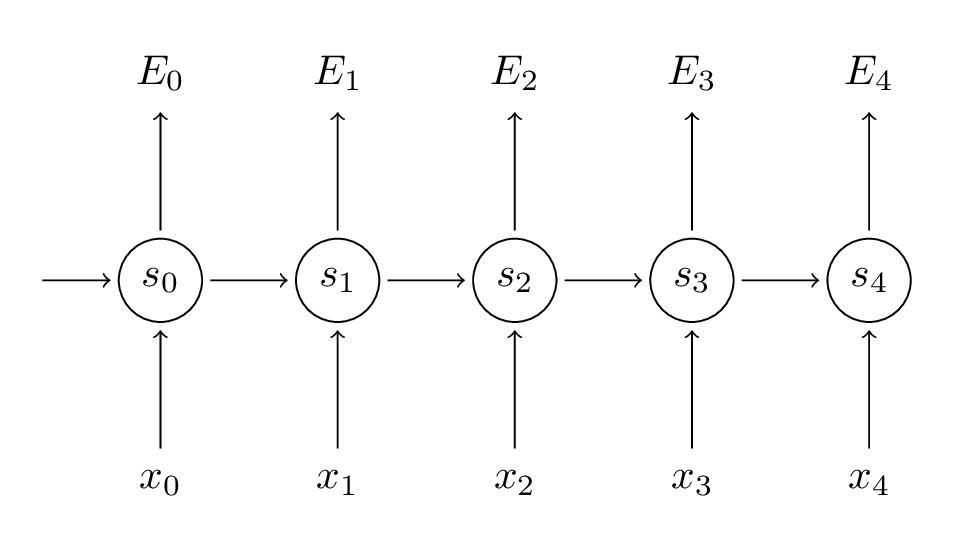
之前提到的简单Feedforward NN中没有weights sharing,在RNN中由于time step间的是一样的,所以在上式中,我们对所有time step关于的梯度取和。其中。我们又知道,故,易证将会是非常大,或是非常小的数(Bengio et al 1994)。
对于Gradient explosion问题,Mikolov提出了用clip gradients的方法解决问题,是通过设置阈值(threshold),如果梯度大于这个阈值,便手动修改梯度。对于gradient vanishing 问题我们的非线性函数采用relu,将w初始化为单位矩阵(这种RNN称为IRNN),可以一定程度上解决问题。
在RNN的基础上,提出了一部分的改进模型,比如bidirectional RNNs,其time step不仅包含的信息,还包含了。
接下来在Lecture9中谈及了Machine Translation的基本模型(encode以及decode两部分RNN组成),以及其五种扩展(model extensions);随后介绍了改进模型Gates Recurrent Units,其改变为Gate,包括Update gate:,以及reset gate:,设置中间值,有,
Deep learning public library:TensorFlow
分类:1)通过configuration file文件完成模型:Caffe,DistBelief,CNTK;2)programmatic generation:Torch(Lua),Theano(Python),Tensorflow(Python)。如我们之前Blog提到的,Theano和Tensorflow是非常相似的,这里选择介绍Tensorflow,其一方面有google的背书,另一方面对分布式计算支持较好(一般模型需要在16核GPU上训练1周之久)。
1. Tensors,用于表示数据,可以看做是n维数组,可以理解为numpy最基础的功能,而TF则在numpy的基础上提供了tensor funciton, 梯度计算,GPU support这些额外的功能。首先介绍了numpy和tensorflow的相似之处,包括metrics的定义,求和以及broadcast性质。然后指出了两者的不同,在numpy中定义metric时,已经在内存中malloc了相应的参数,而在tf中,仅仅是定义了computation graph,直至evaluated(.eval())时才真正create numerical value。
2. Session, 是所有operation的环境,sess.run(y)返回fetch(从global computation graph 从返回的结果),一般将要参与运算的所有tensor定义在同一个session下。tf.InteractiveSession()是在ipython中使用的default session.
3. Computation Graph, every function(),就是在computation graph上加入新内容。Computation Graph会record这些操作。
4. Variables,是boxs that hold states. 与constant tensor的区别是,variable在使用(session.run(v)前必须initialize(tf.initialize_all_variables())。variable为什么需要name:通过name来在computation graph 中进行索引。variable的scope(namespace)问题:,背景:复杂的神经网络模型中可能会有数百个variable,我们需要了解namespace。对于Recurrent NN中的weights sharing,我们使用reuse_varaiables()
5. Inputting data,定义数据。1)方法一是通过numpy定义metric a,使用tf.convert_to_tensor(a)完成;2)tf.placeholder,dummy nodes (相比于numpy的方法,更符合computation graph的定义)that provide entry points for data to computational graph.通过feed_dict完成从placeholder到numerial data 到映射。
Reference
- Stanford cs224d