Ranking & CTR Model
1. Ranking Question
实践中的推荐系统一般包含两类问题:第一类是召回,即挑选出待推荐的候选集;第二类是排序,即对候选集进行排序。
排序,作为信息检索领域的核心问题,这些年来不断以新的形式出现在互联网的方方面面。比如在你在“今日头条”点击了一条刘强东和奶茶妹妹的新闻,在接下来的若干天里,你的信息流首页里,相关的信息将持续排在较高的位置。以上便是在推荐系统(Recommender System)领域中排序的应用。
而将机器学习与排序结合到一起,是近20年以来大家常用的做法。机器学习下的排序问题可以概括为:用户给出一个query, 搜索引擎会匹配出一定数目的documents(候选推荐集), 然后使用机器学习的模型f(q,d)结合用户特征、文章特征以及上下文信息(比如用户对结果进行了筛选)对documents进行排序。 MSRA的刘铁岩将MLR(Machine-learned Ranking)总结为三类:
- Pointwise
认为每一个query-document对都对应一个得分(相关性),因此该类MLR问题可以看作是回归问题,即训练Regreesion Model,来预测每一个query-ducoument的得分,再将document按照得分由高到低进行排序。 - Pairwise
看作是分类问题,比如把点击看做是正样本,展示而未被点击的document看做是负样本。 - Listwise
上述两种类型都没有考虑每个query下所有document之间的序列关系(只考虑了各个document的预测分). 而listwise考虑的是将一个ranking list作为一个instance进行训练,而非document。
有学者把上述MLR方法划分到基于协同过滤的排序(推荐)中,实际上我们能利用的信息不仅仅是用户、商品的ID、以及用户ID与商品ID对应的矩阵(打分(显式反馈)、点击(隐式反馈))。用户、商品的一些别的特征、以及本次用户检索中的上下文信息都可以加入其中,这种排序算法我们称之为基于特征的推荐(Feature-based Recommendation)。
2. Evaluation Measure
对于MLR模型,其算法结果Evaluation的对象与一般机器学习分类器的有一定的不同,前者更关注相对顺序,而非绝对数值。常用的得Evaluation方法包括:
- Normalized Discounted Cumulative Gain(NDCG)
表示从第一个位置到第n个位置的累积折扣信息增益。每个位置的信息折扣增益为:
(1) 其中叫做信息增益(Gain), 为排列在第个文档的相关度,NDCG将相关度分为个等级(比如设为5个等级的话,第1级最差为,第5级最好,为)。
(2) 表示Positive Discount, j越大,该系数越小(大多数机器算法在未提及的底时,默认为)。
(3) 为正则项,加入其的目的是使不同查询之间的DCG可以比较。一般地,取为当前检索结果所有文档按相关度由高到底排列是计算出来的DCG。
因此,最大化NDCG来使好的结果排在靠前的位置。
- MAP(Mean Average Precision)
k个query的准确率的平均。每个query准确率的定义为:, 其中为Precision, 为相关性判断:取0和1。
3. Common Ranking Models
- RankNet
由于上述常用的评价函数不是连续可导的,因此无法通过梯度下降的方法训练分类器的参数。RankNet将目标函数替换机器学习中对于概率问题常用的目标函数:最小化Cross-Entropy(其实是连乘形式的极大似然估计取log,所以又叫做negative log likelihood,该式同时又为香农信息熵公式+相对熵(KL)化简之后的结果):
其中表示文档的算分函数得到的文档得分。表示文档应该排在文档前面的概率,根据实际情况(信息增益等指标)取0, 和1。我们引入来替代,当文档比好时,我们令,两文档相等时取0,否则取-1。即有:。则上式可以修改为:
是由分类器估计出来的文档的得分后,计算出来的应该排在文档前面的概率。一般定义:
因此我们将问题的目标函数转化为可微(可以通过梯度下降法来训练分类器)。
- LambdaRank
这里我们来推导一下RankNet的梯度,来说明使用该梯度训练出来的模型可能具有的一些「我们不期望得到的」性质。
其中
在LambdaMart作者给出的文章中,将上式(1)中的ln2忽略,可以得到:
因此,我们有:
那么对于单个文档其移动的“方向”和“力度”取决于:
而对于有序的pair:(i,j),有,我们将更关心头部结果的NDCG加进来,手动修改的定义:
其中表示文档对(i, j)互换位置之后NDCG的变化量。
- LambdaMart
使用MART(GBDT)作为LambdaRank中的打分器,即为LambdaMart算法。
4. Other Feature-based Models
业界大部分的Ranking模型直接直接使用CTR(点击率预测模型)预测用户点击的可能性高低,然后按可能性高低对其排序。最经典的CTR模型是LR(Logisitc Regreesion),其主要遇到的问题是需要手动的特征离散化、特征组合。GBDT是另一种比较经典的模型,由于是基于树的模型,所以其能够较好地处理连续型的特征。另外一个优点是完成了一定程度的特征组合(树的纵向深度)和特征离散化(分支),但其对于大量高维度的特征难以较好地处理(由于树的数目、深度等限制)。首先一个经典的模型就是将两者进行结合。
- 4.1 GBDT + LR
2014年Facebook给出其在AD Click Predicting的一种实践:Decision Tree + Logistic Regression。该文章指出直接使用GDBT容易造成过拟合,而将样本数据到GDBT叶子结点的索引(Leaf Index)作为Embedding Vector,输入到逻辑回归里。
"""
使用XGBoost对test集合进行one-hot encoder
"""
# step 1: bst为XGBoost训练得到模型,通过训练集1,获取one-hot样本数据
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
ytrain1_leaf_index = bst.predict(dtrain1, pred_leaf=True)
ohe.fit(ytrain1_leaf_index)
# step 2: 将保留的第二部分训练集转化成one-hot
ytrain2_leaf_index = bst.predict(dtrain2, pred_leaf=True)
ohe_feature = ohe.transform(ytrain2_leaf_index)
# step 3: Training LR
from sklearn import linear_model
lr = linear_model.LogisticRegression()
lr.fit(ohe_feature, y_test)但是该方法还是未能存储大量高维度的特征(比如用户ID,商品ID),这时可以将除了这些维度之前的所有特征作为GDBT的输入,而将id类离散特征与GDBT的输出进行组合,放入到LR模型中。
- 4.2 Factorization Machine(分解机)
特征工程中一个重要的环节是特征组合,但在实际的操作中,由于特征离散化(One-Hot编码)等操作,导致原始数据维度十分大,一旦再进行维度组合,将会出现维度爆炸问题。 最后形成的特征矩阵是一个高维度的稀疏矩阵。Factorisation Machine通过直接构造模型,“自动化”地完成特征组合操作。分解机其实是借鉴了基于协同过滤推荐方法中的矩阵分解的思想(这里只是将维度从用户ID、商品ID扩展到了用户、商品的各种维度),即通过构造用户、商品的隐向量,使用其点积作为预测值。考虑二阶的原始维度为n个的特征组合,其模型的表达式如下。
可以看出为了训练,往往需要大量非零的,这对于稀疏的矩阵来说是不现实的,因此直接对该回归函数进行训练,不妥。
考虑到可以表示为一个矩阵(对角元素可以手动修改为正实数),该矩阵可以进行分解(类比与用户对商品的打分矩阵可以分解为用户矩阵(每个用户通过一个隐向量表示,商品也是)和商品矩阵的乘积形式),因此V中第列便是第维特征的隐向量。故问题转换为求解分解后的矩阵V,模型的表达式修订下式,其中为向量的点积:
上述变化有两点好处
-
二次项的系数由减小到其中为隐向量的维度,因此参数的数目大大降低。
-
任何包含特征的样本数据,都可以用来学习隐向量,这种很大程度上避免了数据稀疏情况下,仍需要包含两个维度上都非零的样本数据来学习的窘境。
剩下的问题,和传统的回归问题无异。比如可以用MSE作为损失函数;在比如作为分类问题时,同LR使用Sigmoid处理输出结果y。一般地,可以给出FM模型的训练步骤:
- 初始化权重
- 梯度的方法,迭代更新各参数
台湾大学的Yu Chin Juan基于FM提出了Field-aware Factorization Machine(FFM)模型,其认为同性质的特征可以被归到一个Field上,比如男,女同属于性别Filed;游戏和化妆品分属于商品类别Field;1月1日和10月1日分别属于日期Filed。而做特征组合时,性别Filed=男这个特征与商品类别和日期进行关联时,使用不同的隐向量。其可以表达为:
其中为第个特征所属于的field。该模型共有nf为隐向量,nfk个组合参数。
- 4.3 Deep Learning Model
将深度学习与推荐排序结合到一起可以有两个切入点:
-
4.3.1 使用深度学习进行特征抽取(Extracting Side Features with Deep Learning)
了解CNN的用户应该知道,其模型其实可以拆分为两层;第一层为特征提取层(Conv Layer, Pool Layer),第二层为全连接分类层(Fully Connected Network)。其在ImageNet等数据集上之所以能取得成功,是因为其特征提取层能够抽象出图像多方面、多层次的特征。
在推荐排序领域,多数的工作采用矩阵分解的思路分别对用户、产品训练其隐向量(Embedding Vector)。常用的训练模型包括多层感知机(MLP)、去噪自动编码机(DAE)等。
此外也有尝试将上述得到的隐向量和基于协同过滤模型得到的隐向量结合(相加),从而得到两者的优点(比如前者模型能一定程度上解决Cold Start问题)。 -
4.3.2 深度交互函数学习(Learning Interaction Function)
另外一种操作是在通过一定方法得到用户、商品的隐向量之后不直接进行内积运算得到预测结果,而是把两个隐向量作为神经网络(比如Averaging Pool层+全连接层)的输入去学习“交互函数”来得到预测结果,该模型被称为NCF(Neural Collaborative Filtering);
上述使用Averaging Pool层是假设各个原始One-Hot编码的输入是相互独立的,这里进一步改进Pool层,使用Bilinear Pooling层,相当于参考了分解机,引入了Feature的组合。该模型称为attribute-aware NCF.
Wide&Deep以及Deep Crossing模型分别是Google和MS在2016年提出的模型。其将部分维度进行Embedding学习,再与部分未Embeddingd的维度进行拼接(Concatenation)然后进行MLP学习,最后一层是一个Softmax分类器。两家的区别是MS家多了一层Residual component解决梯度弥散问题。理所当然的,在维度拼接层,可以引入Bilinear Interaction Pooling:
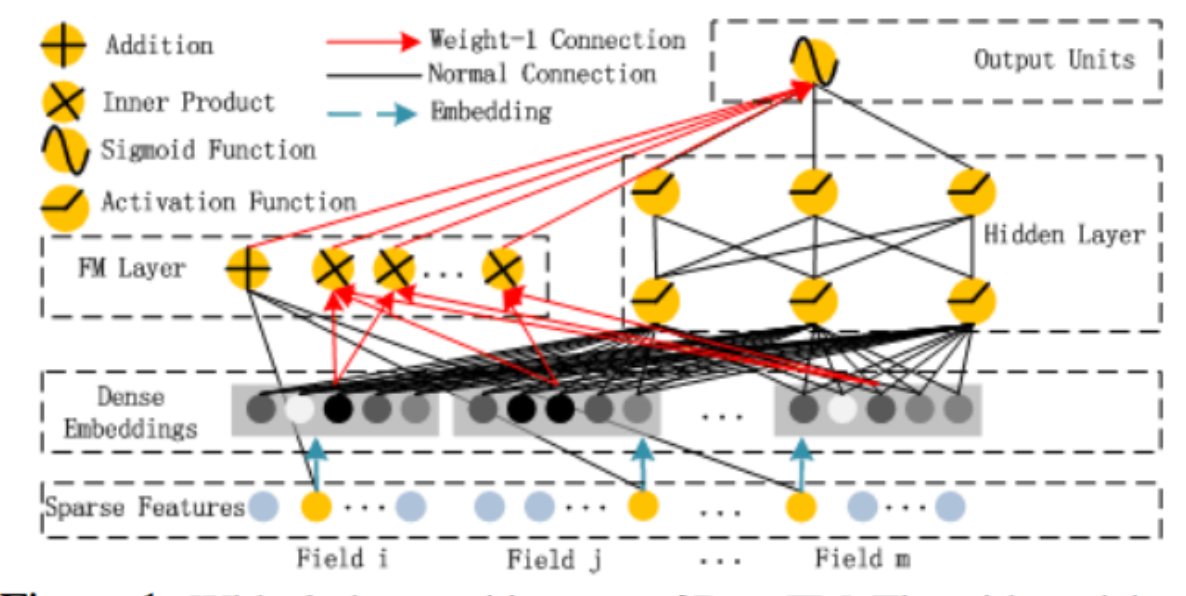
有模型尝试将FM与深度学习模型结合,使用FM进行Embedding,深度学习做分类器。在FM层,对各个Category Field分别做FM回归。比如一共有100个Category Field则最终得到一个100维的Embedding。然后把这100维数据作为深度模型的输入。哈工大深研所和华为借鉴Wide&Deep的思想,将Wide中的广义线性模型替换成FM,除了此外Wide&Deep模型的Wide端和Deep端的输入不尽相同,因此仍需要“特征预筛选”。而这篇文章直接修改成了一个端到端的模型。
附(推荐&排序领域常用术语):
- CTR(Click Through Rate) 点击达成率,实际点击次数/展示次数。
- CPC(Cost per Click) 点击成本,成本/Click次数。
- CVR(Conversion Rate) 从用户点击到最终完成注册或购买的转化率。
- Factorization Machine 分解机,一种自动设置特征组合的回归方法。
- Lookalike 人群扩散,通过一批已有活跃用户(种子用户),找到潜在的客群。思路是挖掘种子用户的典型特征,然后在全量用户群(比如说腾讯的Wechat)